Ensō: A PS Vita bootloader exploit
HENkaku Ensō, the first ever permanent jailbreak (also known as a custom firmware) for all PlayStation Vita devices running home menu version 3.6 was released by molecule on 2017-29-07.
In this blog post I’ll explain how I found the vulnerability and how the exploit was developed and debugged. The rest, i.e. actually loading the jailbroken CFW, is covered in this follow-up article by Yifan Lu.
You might notice how in the linked post Yifan refers to Ensō as “one of the first vulnerabilities we found was in the bootloader”. This is an obvious lie, I found this vulnerability all by myself, trust me. Now that we’re clear on that, please carry on reading.
Introduction
Bootloaders are a great target to exploit. Taking over the boot process early on lets us execute our code before the system has finished initializing, allowing for much more control compared to a more traditional exploit chain such as HENkaku. In some cases it might be possible to create a future-proof exploit, i.e. being able to keep the exploit working and having latest firmware’s features (for example, support for newer games) at the same time. Unfortunately, this is not the case with Vita and Ensō, but hacking the bootloader is still worth it.
Terminology
- ASLR: Address space layout randomization. The important thing here is that Vita bootloader doesn’t have it, so a memory corruption can be turned into an exploit fairly easily.
- ARM: The main Vita processor is a quad core Cortex-A9. In addition, Vita has a security processor, which is a Toshiba MeP, a MIPS processor used for PSP compatibility, a bunch of PowerVR GPU cores using two custom assembly languages, syscon: an external Renesas chip, and more.
- TrustZone: The CPU supports ARM TrustZone technology, which isolates so-called “trusted” code from the rest of the system. For the purposes of this article, however, you just need to know that it is somewhat of a one side barrier between trusted (aka secure) and untrusted code, allowing trusted code to gain control over untrusted but not vice-versa. Execution starts from secure mode and transfers to non-secure.
- SBL: secure boot loader. This is the first code that runs on ARM. It sets up NSBL (see below) and transfers control to it after dropping out of the secure mode.
- NSBL: non-secure boot loader. This is the first code that runs on ARM in non-secure mode (outside of TrustZone).
- eMMC: This is the primary persistent storage on Vita. It’s where the operating system, bootloaders, and system data are all stored.
Sidenote: Unlike most embedded devices, Vita implements device unique eMMC block level encryption that is transparent to the processor. This means that if you dump the data from the chip (or sniff data lines), you’ll get encrypted data. At the same time, Vita operating system will always see the decrypted data, even at the most privileged level of its operation. One consequence of this is that you have to dump and restore the data the same way. For example, if you dump the data using an eMMC adapter, you can’t restore it in software as it will have a layer of encryption unaccounted for, and vice-versa.
- Block: data is read from eMMC in blocks. The physical block size is 0x200 bytes, so reading a single block from eMMC means reading 512 bytes.
Attack vectors
SBL is the first code to execute on the ARM processor. Unfortunately, it takes no controlled input whatsoever, so it is not possible to attack in any way.
The obvious next target is NSBL. Because it reads and loads the kernel, it is also the first code running on ARM where we can affect the execution flow. An example of affecting its execution flow is removing all kernel modules from os0:, which would turn your Vita into a useless paperweight.
The very first step of loading kernel modules is reading and parsing the filesystem they are stored on. Let’s dig deeper into the process.
Partition table
The eMMC storage on Vita is divided into multiple partitions that have different responsibilities. In this post I’ll only look at os0:, however, if you’re interested in the full list, check out the wiki article on the subject.
A partition table stores partitions’ locations, sizes and other miscellaneous information. For example, on Vita we have os0: and vs0: partitions; on Linux you may have /dev/sda1 and /dev/sda2. The partition table is usually stored in the first blocks of the physical device. Common partition table formats used on PC are MBR (also called DOS) and GPT.
On Vita, however, a custom partition table format is used. The first physical block, i.e. bytes [0x000; 0x200), contain the partition table. The structure is documented on the wiki. While not completely accurate, I’ll refer to this block as MBR throughout this article. In pseudocode Vita’s MBR would be:
typedef struct {
uint32_t off;
uint32_t sz;
uint8_t code;
uint8_t type;
uint8_t active;
uint32_t flags;
uint16_t unk;
} __attribute__((packed)) partition_t; // Size = 17 bytes
typedef struct {
char magic[0x20];
uint32_t version;
uint32_t device_size;
char unk1[0x28];
partition_t partitions[0x10];
char unk2[0x5E];
char unk3[0x10 * 4];
uint16_t sig;
} __attribute__((packed)) master_block_t; // Size = 512 bytes
Vita supports up to 16 partitions and each partition entry is 17 bytes. For example:
00000000 53 6f 6e 79 20 43 6f 6d 70 75 74 65 72 20 45 6e |Sony Computer En| 00000010 74 65 72 74 61 69 6e 6d 65 6e 74 20 49 6e 63 2e |tertainment Inc.| 00000020 03 00 00 00 00 00 76 00 00 00 00 00 00 00 00 00 |......v.........| 00000030 6b 40 00 00 6a 00 00 00 00 40 00 00 00 40 00 00 |k@..j....@...@..| 00000040 00 60 00 00 00 80 00 00 00 00 00 00 00 00 00 00 |.`..............| 00000050 00 02 00 00 00 04 00 00 01 da 00 1f 0f 00 00 00 |................| 00000060 00 00 40 00 00 00 20 00 00 02 da 01 0f 0f 00 00 |..@... .........| 00000070 00 00 00 60 00 00 00 20 00 00 02 da 00 0f 0f 00 |...`... ........| 00000080 00 00 00 00 80 00 00 00 80 00 00 03 06 01 0f 0f |................| 00000090 00 00 00 00 00 00 01 00 00 80 00 00 03 06 00 0f |................| 000000a0 0f 00 00 00 00 00 80 01 00 00 00 03 00 0c 06 00 |................| 000000b0 ff 0f 00 00 00 00 00 80 04 00 00 00 01 00 06 06 |................| 000000c0 00 ff 0f 00 00 00 00 00 80 05 00 00 00 08 00 04 |................| 000000d0 06 00 0f 0f 00 00 00 00 00 80 0d 00 00 00 01 00 |................| 000000e0 05 06 00 ff 0f 00 00 00 00 00 80 0e 00 00 00 08 |................| 000000f0 00 0b 06 00 ff 0f 00 00 00 00 00 80 16 00 00 80 |................| 00000100 09 00 0e 07 00 ff 0f 00 00 00 00 00 00 20 00 00 |............. ..| 00000110 00 30 00 07 07 00 ff 0f 00 00 00 00 00 00 50 00 |.0............P.| 00000120 00 00 26 00 08 07 00 ff 0f 00 00 00 00 00 00 00 |..&.............| 00000130 00 00 00 26 00 00 00 00 00 00 00 00 00 00 00 00 |...&............| 00000140 00 00 00 00 76 00 00 00 00 00 00 00 00 00 00 00 |....v...........| 00000150 00 00 00 00 00 76 00 00 00 00 00 00 00 00 00 00 |.....v..........| 00000160 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000001f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa |..............U.|
Yellow: idstorage; Cyan: active SLB2; Pink: inactive SLB2.
Note that the partition table is not aware of partitions’ contents. As such, there is a disconnect between for example how large a partition is in the partition table and how large the target filesystem is. The filesystem itself also isn’t aware of where it’s placed on the disk, so all offsets are relative to its first block.
Some important partitions, for example, os0: where kernel modules and other system files are stored, have a shadow copy. This is done so that a system update doesn’t brick your console if you lose power in the middle of it. The updater first overwrites the inactive os0 with the new version and then flips the active bit around. Since flipping the active bit is very fast, it is very unlikely that you’d lose power at that exact millisecond.
FAT file system
The os0: partition uses the FAT file system. The first block of the partition, called FAT boot sector, stores system data such as number of bytes per sector, number of sectors per head and number of heads per cylinder. For flash memory, like Vita uses, the concepts of cyliders or heads don’t make sense, but they are still present.
Normally, the boot sector looks like this:
00000000 eb fe 90 53 43 45 49 20 20 20 20 00 02 08 02 00 |...SCEI .....| 00000010 02 00 02 00 80 f8 13 00 3f 00 ff 00 00 00 00 00 |........?.......| 00000020 00 00 00 00 80 00 29 22 40 77 48 4e 4f 20 4e 41 |......)"@wHNO NA| 00000030 4d 45 20 20 20 20 46 41 54 31 36 20 20 20 00 00 |ME FAT16 ..| 00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000001f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa |..............U.|
The vulnerability
At offset 0xB in the FAT boot sector there is a 16-bit value called BytesPerSector (marked in red). On Vita it is set to 0x200 to match the physical sector size.
The function that parses the boot sector is located at 0x5101FD18 in 3.60 NSBL. At some point it reads the field:
fat_bytes_per_sector = *(unsigned __int16 *)&fat_cache_2.magic[0xB];
fat_bytes_per_sector_minus_1 = *(unsigned __int16 *)&fat_cache_2.magic[0xB] - 1;
And then there’s a check at the end of the function:
if ( fat_bytes_per_sector_minus_1 >= 0x200 )
return 0x803FF003;
It seems that if we set BytesPerSector to a large value, e.g. 0x400 it would error out and Vita would refuse to boot.
Sidenote: Notice how it compares not the original BytesPerSector, but rather a calculated BytesPerSector - 1. This is likely an optimization made by the compiler. The original code probably looked like:
if (BytesPerSector == 0 || BytesPerSector > 0x200) { error out }
In our case, if BytesPerSector is zero, then BytesPerSector - 1 would be 0xFFFFFFFF, and would also fail the optimized check.
But let’s look deeper. The function with the check described above, which I’m going to call fat_buggy_func, is called from another function located at 0x5100124C that I’ll name setup_emmc. This one does:
// ...
v8 = &os0_dev;
result = fat_buggy_func(v8, 0x110000, v9, v10);
// ...
return result;
Further, setup_emmc itself is called from the function responsible for loading the modules, located at 0x5100163C:
// ...
cpu_barrier_start2(0);
if ( !get_cpu_aff() ) { // if executed on CPU0
setup_emmc();
// ...
Oops! Turns out, this one doesn’t use the return value at all! Therefore, NSBL will proceed even though BytesPerSector is now 0x400.
Since fat_buggy_func had returned early with an error, some code inside it did not execute and some variables were left uninitialized. Fortunatelly, it doesn’t matter for our exploit.
Looking for code that would use our BytesPerSector I found a function at 0x5101F56C. This is what I’ll call exploited_fat_func. It has the following loop:
while ( 1 )
{
if ( *v73 )
{
v12 = (*v73)(dword_511673A0, v69, blocks_per_sector >> 9, temp_store);
}
else
{
raw_block_read = *(int (__fastcall **)(_DWORD, int, unsigned int, char *))(v68 + 84);
if ( !raw_block_read )
goto LABEL_42;
// we'll exploit this call below
v12 = raw_block_read(*(_DWORD *)(v68 + 88), v69, blocks_per_sector >> 9, temp_store);
}
if ( v12 < 0 )
goto LABEL_42;
blocks_per_sector = *(_DWORD *)(v68 + 80);
v13 = blocks_per_sector >> 5;
if ( blocks_per_sector >> 5 )
break;
LABEL_49:
if ( ++v69 == v77 )
{
v8 = v11;
goto LABEL_51;
}
}
raw_block_read is a function pointer. It reads 0x200-sized blocks from the flash.
blocks_per_sector >> 9 is equivalent to blocks_per_sector / 0x200, so it calculates how many blocks a sector is made of and reads that much from the flash memory.
The data is read into temp_store which is a global array 0x200 bytes in size. Now that we’ve managed to set blocks_per_sector to 0x400, it will overflow the array and corrupt the data after it.
The function pointer, raw_block_read, is loaded from v68 + 84. v68 is a pointer to os0_dev, which is also a global variable. It is located at 0x51167784, while temp_store is located at 0x511671A0. As such, we can corrupt the whole structure including this function pointer by setting blocks_per_sector to e.g. 0x800.
Now if the loop executes at least twice, on the first iteration it will corrupt the function pointer and on the second it will execute our code!
Debugging the exploit
Since any mistake here would result in a permanently bricked console, testing the exploit requires a modified Vita system so that one can restore eMMC contents at any time. At the time I didn’t have access to one, so the initial testing was done on QEMU.
By mapping bootloader image to 0x51000000, stubbing some functions (e.g. changing raw_block_read to read from file instead of implementing the HW interface), we created a test environment that allowed for rapid prototyping of the exploit.
Sidenote: Vita has 4 ARM cores. You can think of it as 4 separate CPUs. When the non-secure world starts, all CPUs start executing NSBL from the first instruction at the same time.
The cpu_barrier_start and cpu_barrier_end functions make sure that different CPUs execute same code sequentially. For example, in pseudocode:
cpu_barrier_start()
some_function()
cpu_barrier_end()
some_function() would be called sequentially by CPU0, CPU1, CPU2, CPU3, and only a single CPU would execute it at a time.
However, there is a bug in these barrier functions. Can you find it? This bug never shows on real hardware, but on old QEMU it prevents us from going past the first barrier so I had to fix it. Here’s the code listing, including supporting functions.
What’s the best part about using QEMU? You get console output!
What’s even better? You get debugging too!
It turns out that in addition to having no ASLR in the bootloader, it is also entirely mapped as RWX. At this point developing the rest of the exploit was a breeze. What I did was overwrite the function pointer with a pointer to the global buffer, then write our shellcode to the buffer. Soon I had a payload which did a printf (that you cannot see on real hardware) and another one which blinked the PS button led.
Testing on real hardware
I had davee help me test the payload on a real Vita which had a eMMC hardware mod implemented. Unfortunately, it did not work at all. The reason for that is that ARM is not instruction/data cache coherent. (which I really should’ve remembered but at the time was blinded by the excitement of having a boot time hack)
What that means is that you cannot just write code into RWX memory and jump into it – you have to writeback the data cache first and then flush the instruction cache. So even though there’s RWX memory and we have our code already there, we still have to implement a ROP chain to perform cache maintenance.
Fortunately, we have all the pieces already. We control the function pointer and also R0 (it is the first argument to the function, it’s loaded from v68 + 88 and we control data around v68). We also have our controlled data put at a known address, and NSBL has all the gadgets and cache maintenance functions we might ever need.
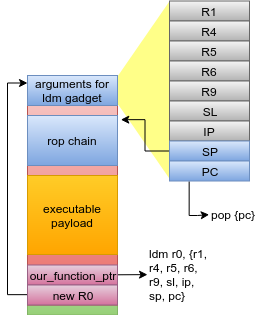
To kick off the ROP chain I used this LDM gadget that loads both PC and SP from R0 as a pivot:
0x51014f10 e890b672 ldm r0, {r1, r4, r5, r6, r9, sl, ip, sp, pc}
From there, the ROP chain calls data cache clean (also known as writeback on other architectures), instruction cache flush, and finally jumps to the payload. You can find the full ROP chain here.
Payload
Ultimately, we want Vita to boot. However, since 0x800 bytes of data section are corrupted, the bootloader now is in a weird state with a completely broken os0_dev. Not only is it overwritten, but there’s no actual “filesystem” in place, it’s just our hacked up boot sector.
We have to restore it before the boot can proceed:
- Patch the partition read function. We redirect block 0 to block 1 and in Ensō installer write the original pristine partition table into block 1. We need to do this so that the rest of the system doesn’t use our broken
os0“partition”.
Sidenote: We’re redirecting all reads of block 0 to block 1, but not writes. This means if you read block 0 and then write it back, you’ll implicitly uninstall Ensō. One tool that does this is Sony firmware updater (when flipping active os0 bit), which is also the reason we’ve designed Ensō this way.
However, this results in unintutive and dangerous interactions. For example, if you uninstall Ensō, we restore block 0 and overwrite other blocks used by our payload (including block 1) with empty data. But this also means that if the system tries to read block 0 after the uninstall, it’d get garbage data. Which is why it’s important that any modification to Ensō operation is followed by a reboot.
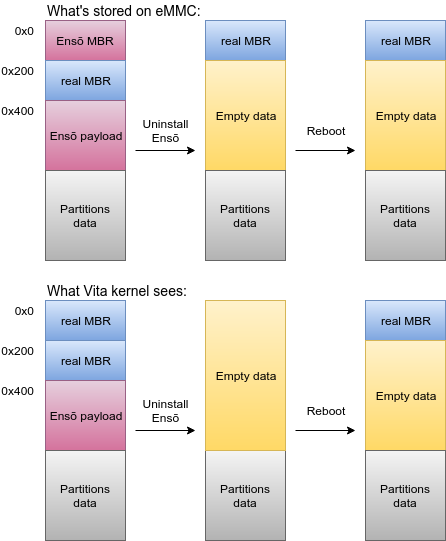
Another failure of our design is that we didn’t provide a way to detect whether Ensō is installed. To make sure we don’t uninstall what’s not installed, the original uninstaller checked block 1 to see if it’s a valid MBR. It then read it and wrote it to block 0. However, if instead of uninstalling Ensō through the application you upgraded your firmware and “implicitly” got rid of it, the block 1 would remain. At this point if you run the uninstaller again (never mind that there’s no reason to do that as Ensō is no longer installed), even if not on 3.60 anymore, it would see valid MBR in block 1, overwrite your real MBR with it and likely brick your console.
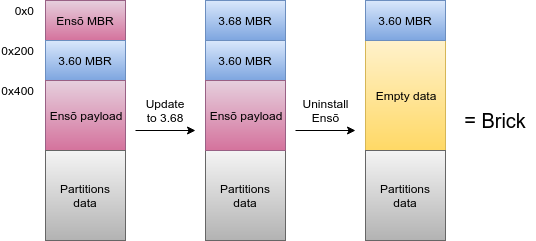
The solution is simple yet perfect – just get rid of that logic. Instead, always read block 0 and write it back.
- Reinitialize
os0_devso that it points to the correct partition and can be read from. - Restore the data we accidentally corrupted with the buffer overflow.
Sidenote: This was one of the show-stoppers during the development of Ensō. One of the more important things we overwrite is sysroot which stores a ton of console-specific information. Initially, I developed the exploit on an earlier firmware where the different layout of NSBL ensured that nothing important is overwritten. On 3.60, however, we were stuck. Without a valid sysroot the console wouldn’t get very far in the boot process. The sysroot is also generated by an earlier boot stage, so there’s no way to recreate it. Fortunately, Yifan has found out that just before our vulnerable code is executed, the sysroot is copied by NSBL to a different place, and we can easily copy it back. Crisis averted!
- Load the larger payload. It does some magic to make sure HENkaku and taihen are loaded on boot. Yifan wrote that one so it’s probably full of bugs, but you can check out his writeup here if you care.
- Restore the context and resume boot, as if nothing had happened.
When we enter the executable payload, sp is somewhere inside our ROP chain (which is somewhere inside the data section, near the os0_dev structure). The very first thing the payload does is change sp to unused scratch area so that our C code doesn’t turn the data section into garbage.
Once we’re done with our hooking and patching though, we want Vita to continue its boot process. But remember that our payload got called in the first place because of the exploit – while executing an NSBL function the bootloader just jumped into our code! And there’s nowhere for our payload to return, as it’s using a separate stack set up by the pivot gadget.
There’re multiple solutions to this problem. For example, one could reimplement NSBL from scratch, or clean it up and trigger a soft-reboot. However, I’ve solved this issue by “restarting” the exploited_fat_func from the point we took over. I did that by restoring corrupted registers to their original values, including the original SP. It is similar to how setjmp and longjmp work, although I never bothered to explicitly save the original values, instead, they are recalculated. Here’s the code:
// restore context and resume boot
uint32_t *sp = *(uint32_t**)(0x51030100 + 0x220); // sp top for core 0
uint32_t *old_sp = sp - 0x11d;
// r0: 0x51167784 os0_dev
// r1: 0xfffffffe
// r2: sp - 0x110
// r3: 0
__asm__ volatile (
"movw r0, #0x7784\n"
"movt r0, #0x5116\n"
"movw r1, #0xfffe\n"
"movt r1, #0xffff\n"
"mov r2, %0\n"
"mov r3, #0\n"
"mov sp, %1\n"
"mov r4, %2\n"
"bx r4\n"
:
: "r" (sp - 0x110), "r" (old_sp), "r" (0x5101F571)
: "r0", "r1", "r2", "r3", "r4"
);
And from that point the boot continues normally and your Vita boots straight into HENkaku. Isn’t that great?
Bricks & lessons learned
There were two bricks during the private testing period and ~3 bricks because of the uninstaller bug described above. Unfortunately, we didn’t learn about the brick bug fast enough because people reported it on various forums instead of using our issue tracker (which is also our fault as we didn’t provide a clearly visible URL pointing to it).
Having said that, with over 270,000 downloads as reported by GitHub, I consider this release a huge success. At the same time, there are still things we could’ve done better. The obvious one is lack of a way to detect whether Ensō is installed, but there’re also other ideas I’ve been thinking about such as auto-uploading installer logs to our server, checking for installer updates at startup, and a user-friendly way to update taiHEN and HENkaku kernel modules.
Hopefully, our experience will serve as a great example of why dangerous code like the installer cannot be too safe. While we did have a ton of safety checks, including reading back blocks after they are written and checking they’re intact, we still missed a bug that resulted in a few bricks. Fortunately, as it is fixed now, there are no more bugs left and Ensō installer is the first ever example of bug-free C code!
How Sony fixed it
The vulnerability was fixed by Sony in firmware 3.67, which means firmwares 3.60 to 3.65 (and potentially everything before 3.60) are exploitable. They added the missing return value check and a panic call inside setup_emmc after fat_buggy_func is called.
result = fat_buggy_func(/* ... */);
os0_ret = result;
// ...
if ( os0_ret )
panic(/* ... */);
In addition, they sprinkled BytesPerSector checks over various read-related functions, so even if by some miracle one manages to bypass the panic call, the moment e.g. sceIoRead is called, your Vita would explode.
Epilogue
The vulnerability here conceptually is way simpler than the HENkaku one, just a trivial global buffer overflow. The lack of the usual mitigations (ASLR, read-only code, etc) also makes it really easy to exploit. On the other hand, there’s way less attack surface (i.e. zero syscalls) compared to the whole kernel and you kind of need to be good at soldering to attempt the hardware mod.
Existence of another vulnerability in NSBL is mathematically impossible in this new paradigm. In a sense, we got very lucky with the Ensō one as other than this really obvious issue (sabotage by a disgruntled Sony employee? ヽ(°〇°)ノ) there’s not much left in NSBL.
That’s all for today, thanks for reading!
Acknowledgements
I’d like to thank Yifan Lu for proofreading the initial version of this article.